Union & Find 란?
유니온 파인드 (Union & Find)는 Disjoint set으로도 불리는 일종의 자료구조이다. 그래프 문제에서도 그래프 문제가 아니어도 자주 등장하여 활용되어지는 친구이다. 보통 각 요소들을 묶어주고, 둘이 같은 그룹에 속해 있는지에 대한 판별등을 해줄 수 있고, 그러한 연산들이 필요할 때 사용되어진다.
기본 로직 소개
Union & Find 는 보통 두 개의 함수로 이루어져있다. 하나는 두 개의 요소를 받아서 두 개의 요소가 포함된 각각의 그룹을 묶어주는 함수이고, 하나는 하나의 요소를 받아서 그 요소의 조상을 알려주는 함수이다. 방금 조상이라는 표현에서 알 수 있듯이 한 그룹내에서 요소를 묶을때 상하관계가 존재하게 되며 한 그룹의 조상은 하나만 존재한다.. 또한 묶을 때는 각 요소의 조상을 구해 한 조상의 부모를 다른 조상으로 지정해 주는 방식으로 진행한다.
구현 방식 & 코드
사실 진짜로 내용이 크게 없고 다른 자료구조를 사용하는 것도 아니라서 딱히 크게 강조할 내용이 없다. 오히려 시간 복잡도 측면에서 이야기 할 부분이 있는데 이를 이야기 하기 위해서 코드를 먼저 보여드리려고 한다.
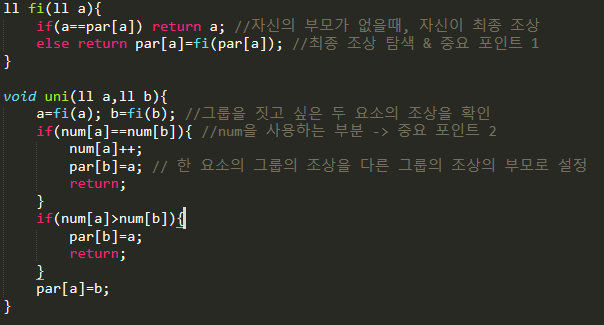
fi 함수는 find를 줄인 것으로 한 요소의 그룹의 조상을 확인 하는 함수이다. uni 함수는 두 요소가 속한 그룹을 합치는 함수이다. 또한 이 코드를 사용하기 위해서는 par[i]=i; 로 초기화를 해주어야 할 것이다. 이때, 코드에서 중요한 부분이라고 강조한 부분이 시간복잡도를 줄이는 최적화 부분이다.
시간 복잡도 최적화
1)
먼저 두 번째 포인트부터 이야기를 해보려고 한다. 구현방식은 두 가지가 있는데 둘 다 목적은 같다. 한 그룹의 깊이를 log 스케일로 내리는 것이다. 위에 작성한 코드에서 num[i]는 i가 조상인 그룹의 깊이를 뜻한다. 이때 깊이가 더 작은 그룹을 큰 그룹에 붙이게 되면 두 그룹의 깊이가 같을때만 그룹의 깊이가 증가하게 된다.
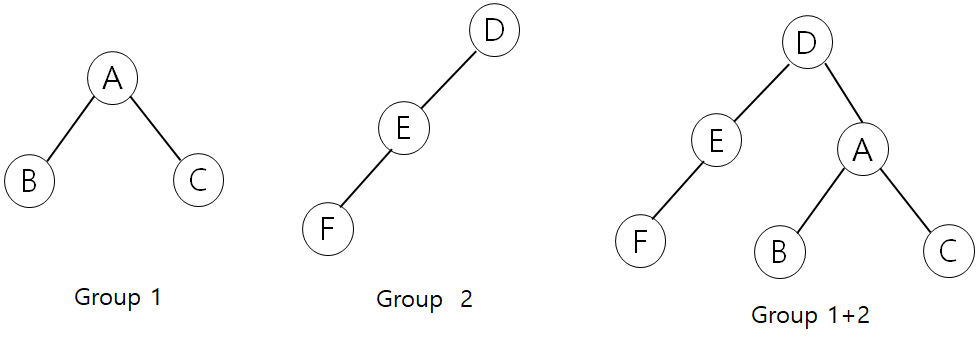
위의 예제를 보면 group2의 깊이가 더 크므로 1의 조상을 2의 조상에 붙인다. 이때 group2의 깊이는 변하지 않는다. 따라서 그룹의 깊이는 log 스케일이 된다. 그래서 어떤 한 요소의 조상을 구하는데 (fi 함수를 돌리는데) 걸리는 시간복잡도는 O(logn)이다.
2)
위의 코드의 중요포인트 1의 부분을 보면 return fi(par[a]) 을 해도 되는데 par[a] = fi(par[a]) 로 하는 것을 볼 수 있다. 이렇게 하게 되면 지금 거쳐가는 모든 요소들을 조상 바로 밑에 붙여주는 효과가 있다. 따라서 다음번에 구할 때 O(1)이 되고, 이를 경로 압축이라고 한다. 아래 예제를 보면 더 이해하기 쉬울 것이다.
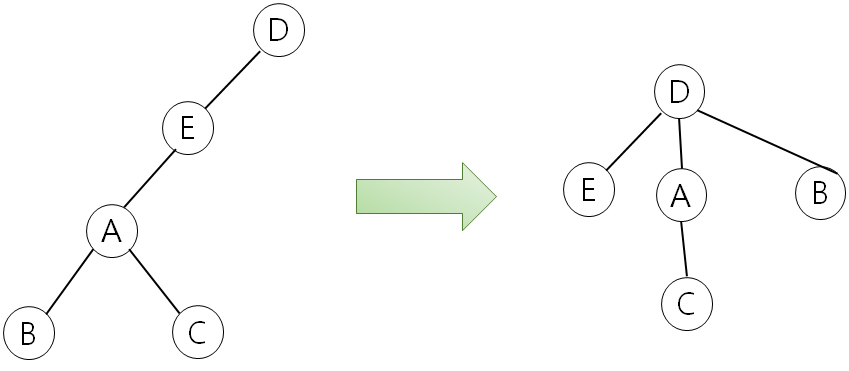
위의 코드에서 재귀함수를 돌다보면 B,A,E를 지나치는데 그 과정에서 이들의 부모를 그룹의 조상으로 바꿔준다. 그래서 fi 함수에 B를 넘겨주면 오른쪽과 같이 경로 압축이 된다.
*위 의 두가지 과정을 다하면 시간복잡도는 역 애커먼 스케일로 하나만 사용햇을때의 스케일 보다 작지만 상수가 크기 때문에 보통 두 가지 압축중 하나만 사용하는 것이 더 빠르다.
굉장히 코드고 간단하고 실행도 빠르며 쓰이는 곳도 많기 때문에 꼭 알아두어야 한다. 또한 그룹의 크기를 알아야 한다던지 index가 작은 곳을 붙여야 한다던지 다양한 방식으로 개조해야 한다. 따라서 union & find 의 작동원리를 완벽히 파악하고 다양한 방법으로 활용할 줄 알아야 한다. 실제 코드에 적용시켜 보고 싶다면 MST를 공부하여 코드를 써보자.
'코딩 > 알고리즘 & 자료구조' 카테고리의 다른 글
| Segment Tree With Lazy Propagtion (0) | 2020.02.29 |
|---|---|
| 알고리즘 & 자료구조 복기글 (6) Segment Tree (0) | 2020.02.19 |
| 알고리즘 & 자료구조 복기글 (4) - 최소 스패닝 트리 (0) | 2019.11.29 |
| 알고리즘 & 자료구조 복기글 (3) - 다익스트라 (0) | 2019.11.24 |
| 알고리즘 & 자료구조 복기글 (2) - BFS 와 DFS (0) | 2019.11.19 |